I’ve been talking about language choice and drawing pictures for long enough and feel like I understand the problem space pretty well, so it’s time to start writing some code.
As a standard disclaimer prior to walking through this code, however, I ought to mention that while the Haskell version is only 60 lines, I threw away a ton of work in order to iterate fast. The most notable simplification I made at first was a prototype of the prototype which only allowed one hidden layer. As with any program, assume that a hell of a lot of work went into that simple or compact code.
Alright, first things first, module declaration and imports!
module Neural (NeuralNetwork, buildNeuralNetwork, buildRandomNeuralNetwork, calculateHighestOutputIndex, calculateOutputValues, mutate) where import Data.List import Data.List.Split import Data.Ord import System.Random
This declares a new module named “Neural”, which includes the type “NeuralNetwork”, and the methods buildNeuralNetwork, buildRandomNeuralNetwork, calculateHighestOutputIndex, calculateOutputValues, and mutate.
If I hadn’t included the stuff in parantheses, every top-level function, data type, and constructor would have be accessible via different modules. I do this for two reasons:
1) It’s good programming practice to hide (fancy word: encapsulate) complexity and only expose details to your client if the client absolutely must know about them.
2) If GHC (Haskell’s compiler) realizes that a function is only used within a module it can do a much better job of optimizing the function and stripping away unneeded generality, which means that the code runs faster.
Next we have our data types.
type Value = Double data NeuralNetwork = NeuralNetwork Value [Int] [[[Value]]] deriving Show -- weight values grouped by vertice group, terminus, origin.
I’m not sure whether I want to stick with Double, so I provide an alias for that type called “Value”. This turns out to be a hell of a lot more reliable than brute-force text swaps of the entire file after I’m done with it. Straightforward enough.
Quick syntax node, square brackets in Haskell are shorthand for a linked list.
On the next line, I create a data type called NeuralNetwork which contains a Value, a linked list of bounded Integer values (a square bracket is short-hand for Haskell’s Linked List type) and a, WHOA OH MY GOD, WHAT IS THAT!?!? …It’s a linked list of a linked list of a linked list of (Double) Values.

It’s okay. Remember the picture I drew in Part 2?
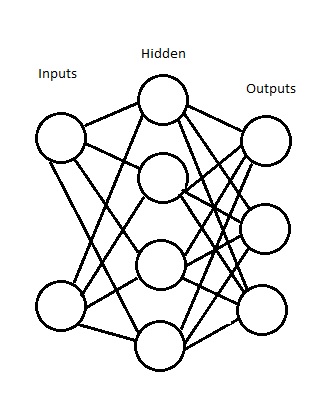
Alright, so let’s look at it one layer at a time:
1) Values. Each value corresponds to the weight on one of those lines.
2) List of values. Each node has a list of edges entering it.
3) List of List of Values. Each layer is a list of nodes.
4) List of List of List of Values. The Neural Network is a list of its layers.
Awesome. Nice chat. Might I suggest some aspirin? It helps (no it doesn’t.)
If this doesn’t make sense right now, I hope it’ll make sense soon.
buildStaticNeuralNetwork :: Value -> [Int] -> NeuralNetwork buildStaticNeuralNetwork mutationRate nodeLayerSizes = buildNeuralNetwork mutationRate nodeLayerSizes []
This method build a “static” Neural Network. One in which all the edge weights are identical and no randomness is involved. This is a useful test method and could be safely deleted in a working implementation, but I still like having it around for unit tests. This is straightforward code: It takes a mutation rate and a list of sizes for each node layer and then calls the buildNeuralNetwork function with them and an empty linked list.
buildNeuralNetwork :: Value -> [Int] -> [Value] -> NeuralNetwork buildNeuralNetwork mutationRate nodeLayerSizes weights | numWeights < numVertices = buildNeuralNetwork mutationRate nodeLayerSizes padWeights | otherwise = NeuralNetwork mutationRate nodeLayerSizes verticeGroups where verticeGroups = map (\(vtg,numOrigins) -> chunksOf numOrigins vtg) (zip groupWeightsByVerticeGroup originLayerSizes) groupWeightsByVerticeGroup = splitPlaces numVerticesByLayer weights numWeights = length weights numVertices = sum numVerticesByLayer numVerticesByLayer = zipWith (*) nodeLayerSizes terminusLayerSizes terminusLayerSizes = drop 1 nodeLayerSizes originLayerSizes = init nodeLayerSizes padWeights = weights ++ (take (numVertices - numWeights) $ repeat 0.0)
This is the first truly complicated function in the module and I’m still not satisfied with it. Its intent is to take a mutation rate, a list of node layer sizes, and a list of weights and produce a Neural Network from them. How it does that is… well, complicated.
If the number of weights is less than the number of vertices, I pad the list of weights with the value 0.0 at the end and then call this function again with the (correct) number of vertices. (The static initialization function takes advantage of this by passing an empty list, which then gets padded with the number of 0.0 values that it needs to actually create a Neural Network.)
In any other case, the function initializes a Neural Network with the provided mutation rate, node layer sizes and vertice groups. Vertice Groups are a complicated topic, so we’ll attack the notion backwards. To make the list of vertice groups, I need each vertice group, which is made by grouping the raw weights we passed in and splitting it up by the number of vertices that each layer requires.
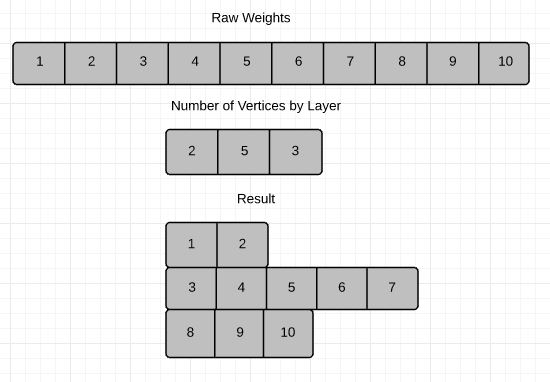
We take the result of this step and then break each list in the result into origin sized chunks, thus generating our list of edges.
All that’s left for our factory functions is to build a randomly initialized Neural Network!
buildRandomNeuralNetwork :: (Value,Value) -> [Int] -> IO NeuralNetwork buildRandomNeuralNetwork verticeRange nodeLayerSizes = do g <- newStdGen let (mutationRate,g') = randomR (1.0,1.0) g randomVerticeValues = take numVertices $ randomRs verticeRange g' where numVertices = sum $ zipWith (*) nodeLayerSizes (drop 1 nodeLayerSizes) return $ buildNeuralNetwork mutationRate nodeLayerSizes randomVerticeValues
The signature up top says that this takes a tuple of values, a list of integers, and produces a NeuralNetwork with the side effect of IO. Haskell’s type system is really awesome in that it tells you right up front if your signatures include side effects. Basically you can read this as “It takes a range of values, a list of integers, and produces a Neural Network which may not be the same as the last Neural Network this function produced.” This makes sense, because it’s creating a randomized list of vertice weights to feed into the function we just got done dissecting.
I’m saving the meat of how this Neural Network does calculation for the next entry in the series, but here’s a sketch of the functions that Neural Network library must have to fulfill my aims:
calculateHighestOutputIndex :: [Value] -> NeuralNetwork -> Int
Given a list of inputs and a Neural Network to pipe them through, return the highest output’s index.
calculateOutputValues :: [Value] -> NeuralNetwork -> [Value]
Given a list of inputs and a Neural Network to pipe them through, produces a list of all outputs.
calculateLayerValues :: [Value] -> [[Value]] -> [Value]
A helper function for calculateOutputValues, given the previous node layer’s values, and the current edge layer, produce the current layer’s values.
mutate :: (Value,Value) -> NeuralNetwork -> IO NeuralNetwork
Given a range of values that a vertice could take and a Neural Network, produce a new Neural Network with one vertice mutated so that it contains a new value.
Bonus Round: But wait, where are the nodes?
The astute reader might be wondering after seeing the last sketch, “Hey, your Neural Network data up at the very top of this article doesn’t have any nodes, but you refer to nodes in these function stubs just now. Where are the nodes?”
In most imperative (think C, C++, Java, C#) Neural Network implementations, nodes are explicitly modeled as part of the structure and the nodes are updated whenever the client calls calculateOutputValues. The nodes essentially act as scratch space — a place to put intermediate calculations before the next round of calculations.
In a pure functional paradigm, this is impossible because data is immutable. Since data is immutable, I lean on Haskell to provide the scratch space for me. In other words, the nodes are artifacts of an object-oriented approach to Neural Network design. Having said that, I suspect allocating the scratch space explicitly as part of a mutable data structure ends up being faster — but this is a prototype — for prototypes, speed is not usually a concern.
