When I set out to design a neural network for this project, I knew very little about neural networks, artificial intelligence, or anything along those lines, and so I can’t say that I chose as I did out of any deep knowledge — what I can say is that a coworker told me that a fully-connected feed forward neural network is easy to implement.
Software Engineering is a constant fight against added, unnecessary complexity so yeah, simplicity, let’s go with that!
So… what’s a fully-connected feed forward neural network and how do I build one?
What’s a fully-connected feed forward neural network?
Let’s take this a term at a time:
Fully-Connected: Every node in layer n connects to every node in layer n + 1.
Feed-Forward: An edge can only point from left to right.
Okay… that still doesn’t make sense to me. Maybe a picture will clear things up.
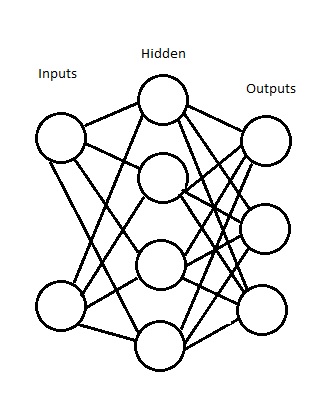
In this picture, both of the inputs connect (the technical term for node is vertice, and the name for a line is an edge, for those who like jargon) to every node in the next layer. Every node in the hidden layer connects to every node in the output layer.
What the sketch doesn’t communicate is how the Neural Network actually works, because there are tons of possible ways to get these nodes to work. You might say that a node (think of it as a neuron in a digital brain) only fires if its signal reaches a certain threshold, for example. I didn’t do that, because I’m dodging complexity. My nodes always fire.
For this simple network then, inputs always fire do to environmental factors. When a node fires, it sends that signal (a value, call it X) across all of the edges it has pointing to the next layer. Each of these edges has a value (call it Y). The next layer node takes its values from applying a squashing function to the sum of all X,Y pairs coming into that node. There’s a lot of argument about what makes a good squashing function, and I’m not experienced at choosing them, so I went with the simple to implement:
1 / (1 + (e^-x)) where x is the sum of all vertice edge pairs entering that node.
Of course, I did add some complexity to my neural network. See that hidden layer in the picture up there? I built my neural network so I can have as many of them as I want, and they can all be different sizes. So much for keeping things simple, huh?
In the next installment of the series, I’ll walk through the working Haskell code for the Neural Network, complete with detailed explanations of what everything does. If you can’t wait until then to take a look at the implementation, you can find it here. If you’re curious about Haskell as a language, I suggest Learn You A Haskell as a jumping-off point. If you’re curious about Artificial Intelligence, AI Application Programming by M. Tim Jones does a good job without getting too mathy.
